Tribune de Guinness, doctorante en informatique et membre de La Quadrature du Net
À l’heure où toutes les puissances de la planète se mettent à réfléchir à des solutions de traçage de contact (contact tracing), les GAFAM sautent sur l’occasion et Apple et Google proposent leur propre protocole.
On peut donc se poser quelques minutes et regarder, analyser, chercher, et trouver les avantages et les inconvénients de ce protocole par rapport à ses deux grands concurrents, NTC et DP-3T, qui sont similaires.
Commençons par résumer le fonctionnement de ce protocole. Je me base sur les documents publiés sur le site de la grande pomme. Comme ses concurrents, il utilise le Bluetooth ainsi qu’un serveur dont le rôle est de recevoir les signalements de personnes infecté·es, et de communiquer aux utilisateurices de l’application les listes des personnes infectées par SARS-Cov2 qu’elles auraient pu croiser.
Mais commençons par le début.
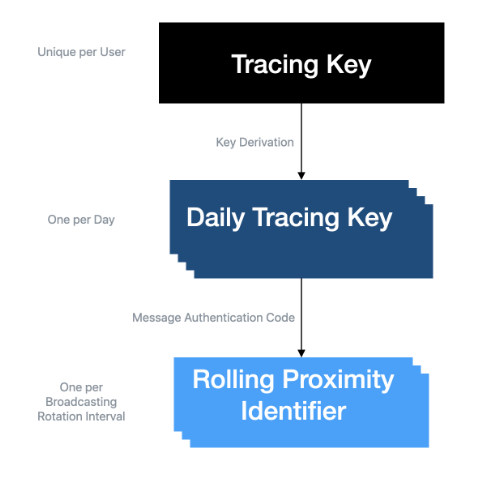
Le protocole utilisant de nombreux protocoles et fonctions cryptographiques, et étant assez long, je ne vais pas l’expliquer en détail, et si vous voulez plus d’informations, vous pouvez vous référer à la note en bas de page.1L’application commence par générer un identifiant unique de 256 bits. Suffisamment long pour qu’il n’y ait pas de risque de collisions (deux personnes qui génèrent par hasard – ou non – le même identifiant), et ce même si toute la population terrestre utilisait l’application. Cet identifiant est appelé Tracing Key.
Puis, chaque jour, un identifiant pour la journée (appelé Daily Tracing Key) est calculé à partir de la Tracing Key. Pour ce faire, on utilise la fonction à sens unique HKDF, qui permet à partir de paramètres d’entrée de générer une clef unique et à partir de laquelle il est impossible en pratique de remonter aux informations d’origine. Dans notre cas, les paramètres d’entrée sont la Tracing Key et le numéro du jour courant, ce qui nous permet de calculer une clef journalière de 128 bits.
Pour la dernière étape, le protocole dérive un nouvel identifiant, celui qui sera communiqué via Bluetooth aux autres utilisateurices de l’application: le Rolling Proximity Identifier (RPI) un « identifiant de proximité continu » au sens où celui-ci change constamment. Il est recalculé toutes les 15 minutes, chaque fois que l’adresse physique de la puce Bluetooth change et on stocke un nombre appelé TINj qui augmente de 1 toutes les 15 minutes de même que j ; à la différence que j est réinitialisé chaque jour. On utilise pour calculer la RPI la fonction HMAC, une autre fonction à sens unique, qui utilise comme paramètres la Daily Tracing Key du jour courant ainsi que le TINj du quart d’heure en cours.
Finalement, la partie intéressante : que se passe-t-il lorsqu’une personne est déclarée infectée ?
L’application crée une clef de diagnostic, qui n’a ici aucune fonction cryptographique : on envoie les dernières 14 Daily Tracing Keys, ainsi que les numéros des jours associés, puis on continue chaque jour d’envoyer les 14 dernières Daily Tracing Keys ainsi que le jour associé (voir ce PDF au paragraphe §CTSelfTracingInfoRequest) . Cette clef est ensuite envoyée sur un serveur qui stocke toutes les clefs de diagnostic.
Par ailleurs, de manière fréquente, les client·es récupèrent la liste des clefs de diagnostic, utilisent ces clefs pour recalculer tous les RPI, et voir si dans la liste des personnes croisées, on retrouve un de ces RPI. Si c’est le cas, on prévient l’utilisateurice.
Pour faire simple, on génère initialement une clef (Tracing Key ou TK), qu’on utilise chaque jour pour calculer une nouvelle clef (Daily Tracing Key ou DTK), qu’on utilise elle-même toutes les 15 minutes pour calculer une troisième clef (Rolling Proximity Identifier ou RPI), qu’on va appeler la «clef roulante de proximité», qui sera diffusée avec le Bluetooth.
Ce qu’il faut retenir, c’est que l’identifiant qui est diffusé via le Bluetooth change toutes les 15 minutes, et qu’il est impossible en pratique de déduire l’identité d’une personne en ne connaissant que cet identifiant ou plusieurs de ces identifiants.
Par ailleurs, si on se déclare comme malade, on envoie au serveur central la liste des paires (DTK, jour de création de la DTK) des 14 derniers jours, et de même pendant les 14 jours suivants. Cet ensemble forme ce qu’on appelle la clef de diagnostic.
Cryptographie
D’un point de vue cryptographique, tous les spécialistes du domaine (Anne Canteaut, Leo Colisson et d’autres personnes, chercheureuses au LIP6, Sorbonne Université) avec lesquels j’ai eu l’occasion de parler sont d’accord : les algorithmes utilisés sont bien connus et éprouvés. Pour les spécialistes du domaine, la documentation sur la partie cryptographique explique l’utilisation des méthodes HMAC et HKDF avec l’algorithme de hashage SHA256. Les clefs sont toutes de taille suffisante pour qu’on ne puisse pas toutes les générer en les pré-calculant en créant une table de correspondance également appelée « Rainbow table » qui permettrait de remonter aux Tracing Keys . L’attaque envisagée ici consiste à générer le plus de TK possibles, leurs DTK correspondantes et lorsque des DTK sont révélées sur quelques jours, utiliser la table de correspondance pré-calculée pour remonter à la TK.
On peut faire un gros reproche cependant : la non-utilisation de sel (une chaîne de caractères aléatoires, différente pour chaque personne et définie une fois pour toutes, qu’on ajoute aux données qu’on hashe) lors de l’appel à HMAC pour générer les DTK, ce qui est une aberration, et pire encore, aucune justification n’est donnée par Apple et Google.
Respect de la vie privée et traçage
Quand on écrit un protocole cryptographique, selon Apple et Google « with user privacy and security central to the design » (Traduction : « avec le respect de la vie privée de l’utilisateurice et la sécurité au centre de la conception »), on est en droit de chercher tous les moyens possibles de récupérer un peu d’information, de tracer les utilisateurices, de savoir qui iels sont.
Premier problème : La quantité de calcul demandée aux clients
À chaque fois que le téléphone du client récupère la liste des clefs de diagnostic des personnes déclarées malades, il doit calculer tous les RPI (96 par jour, faites moi confiance c’est dans le protocole, 96 * 15 min = 24 h) de toutes les clefs pour tous les jours. On peut imaginer ne récupérer que les nouvelles données chaque jour, mais ce n’est pas spécifié dans le protocole. Ainsi, au vu de la quantité de personnes infectées chaque jour, on va vite se retrouver à court de puissance de calcul dans le téléphone. On peut même s’imaginer faire des attaques par DoS (déni de service) en insérant de très nombreuses clefs de diagnostic dans le serveur pour bloquer les téléphones des utilisateurices.
En effet, quand on se déclare positif, il n’y a pas d’information ajoutée, pas d’autorité qui assure que la personne a bien été infectée, ce qui permet à tout le monde de se déclarer positif, en faisant l’hypothèse que la population jouera le jeu et ne se déclarera positive que si elle l’est vraiment.
Deuxième problème : Le serveur principal
Un design utilisant un serveur centralisé (possédé ici par Apple et Google), qui a donc accès aux adresses IP et d’autres informations de la part du client gagne beaucoup d’informations : il sait retrouver quel client est infecté, avoir son nom, ses informations personnelles, c’est-à-dire connaître parfaitement la personne infectée, quitte à revendre les données ou de l’espace publicitaire ciblé pour cette personne. Comment cela se passe-t-il ? Avec ses pisteurs embarqués dans plus de 45% des applications testées par Exodus Privacy, pisteurs qui partagent des informations privées, et qui vont utiliser la même adresse IP, Google va pouvoir par exemple recouper toutes ces informations avec l’adresse IP pour savoir à qui appartient quelle adresse IP à ce moment.
Troisième problème : Traçage et publicité
Lorsqu’on est infecté⋅e, on révèle ses DTK, donc tous les RPI passés. On peut donc corréler les partages de RPI passés avec d’autres informations qu’on a.
Pour aller plus loin, nous avons besoin d’introduire deux notions : celle d’adversaire actif, et celle d’adversaire passif. L’adversaire actif tente de gagner activement de l’information, en essayant de casser de la cryptographie, de récupérer des clefs, des identifiants. Nous avons vu précédemment qu’il a fort peu de chance d’y arriver.
L’adversaire passif quant à lui se contente de récupérer des RPIs, des adresses physiques de puces Bluetooth, et d’essayer de corréler ces informations.
Ce dernier type d’adversaire a existé et existe encore . Par exemple, la ville de Londres a longtemps équipé ses poubelles de puces WiFi, permettant de suivre à la trace les smartphones dans la ville. En France, l’entreprise Retency, ou encore les Aéroports de Paris font la même chose avec le Bluetooth. Ces entreprises ont donc des réseaux de capture de données, et se révéler comme positif à SARS-Cov2 permet alors à ces entreprises, qui auront capté les RPIs envoyés, de pister la personne, de corréler avec les données de la publicité ciblée afin d’identifier les personnes infectées et donc revendre des listes de personnes infectées.
On peut aussi imaginer des implémentations du protocole qui stockent des données en plus de celles demandées par le protocole, telles que la localisation GPS, ou qui envoient des données sensibles à un serveur tiers.
D’autres attaques existent, dans le cadre d’un adversaire malveillant, mais nous ne nous attarderons pas dessus ; un article publié il y a quelques jours (en anglais) les décrit très bien : https://eprint.iacr.org/2020/399.pdf.
Nous pouvons ainsi voir que, même si le protocole est annoncé comme ayant la sécurité et le respect de la vie privée en son centre, il n’est pas exempt de défauts, et il y a même, à mon avis, des choix techniques qui ont été faits qui peuvent permettre le traçage publicitaire même si on ne peut en prouver la volonté. Alors même que tous les pays du monde sont en crise, et devraient investir dans du matériel médical, dans du personnel, dans les hôpitaux, dans la recherche de traitements contre SARS-Cov2, ils préfèrent se tourner vers un solutionnisme technologique qui non seulement n’a aucune assurance de fonctionner, mais qui également demande que plus de 60 % de la population utilise l’application pour être efficace (voir cet article pour plus d’informations).
D’autant plus qu’une telle application ne peut être efficace qu’avec un dépistage massif de la population, ce que le gouvernement n’est actuellement pas en état de fournir (à raison de 700k tests par semaine, tel qu’annoncé par Édouard Philippe dans son allocution du 28 avril, il faudrait environ 2 ans pour dépister toute la population).
Pour plus d’informations sur les possibles attaques des protocoles de contact tracing, en particulier par des adversaires malveillants, je vous conseille l’excellent site risques-tracage.fr écrit par des chercheureuses INRIA spécialistes du domaine.
References